Let me start off by pointing out the obvious. I don’t especially like to be tracked through the internet. I find it creepy and often very unnecessary. And still add some website tracking to this blog. Let me explain.
Why I don’t like website tracking
While I don’t have something generally against website tracking, I also feel like needing to track my every move crosses a boundary for the trust of a website and I intuitively establish when I open up a website. It’s fine if you want to know if I open up a page. Or also the way I click through a website. I’m even happy to share my browser. But what I don’t like is if the website is constantly tracking my presence, if the website would like to know where my cursor is at all times.
And finally, and perhaps most importantly, I don’t want a website to share my data with a third-party provider without getting my consent first. And this is my big grieve: most website tracking is built in such a way that it shares my usage not only across sites, but also across different networks and countries. And that’s what I do not like. That’s why I block many of the analytics providers, including Google Analytics at the DNS level, which makes my life a lot easier.
Look, it’s easy, if you are running analytics that require cookies, or are run by a big ad network or similar, not data from me. Quick and easy.
Website tracking, the privacy way
So I decided to use an open-source project to run some analytics on this blog. That way I keep control over the data and I can ensure the analytics behave in such a way as I’d like. From my standpoint, it is primarily interesting how many page hits a certain page has and a bit more extended where my visitors come from. As such, I store visitors in an anonymised fashion, and I store the page hits. That’s pretty much it.
I can also see the referrer, but many websites, including Mastodon, do not forward the referrer, which is fair enough for me.
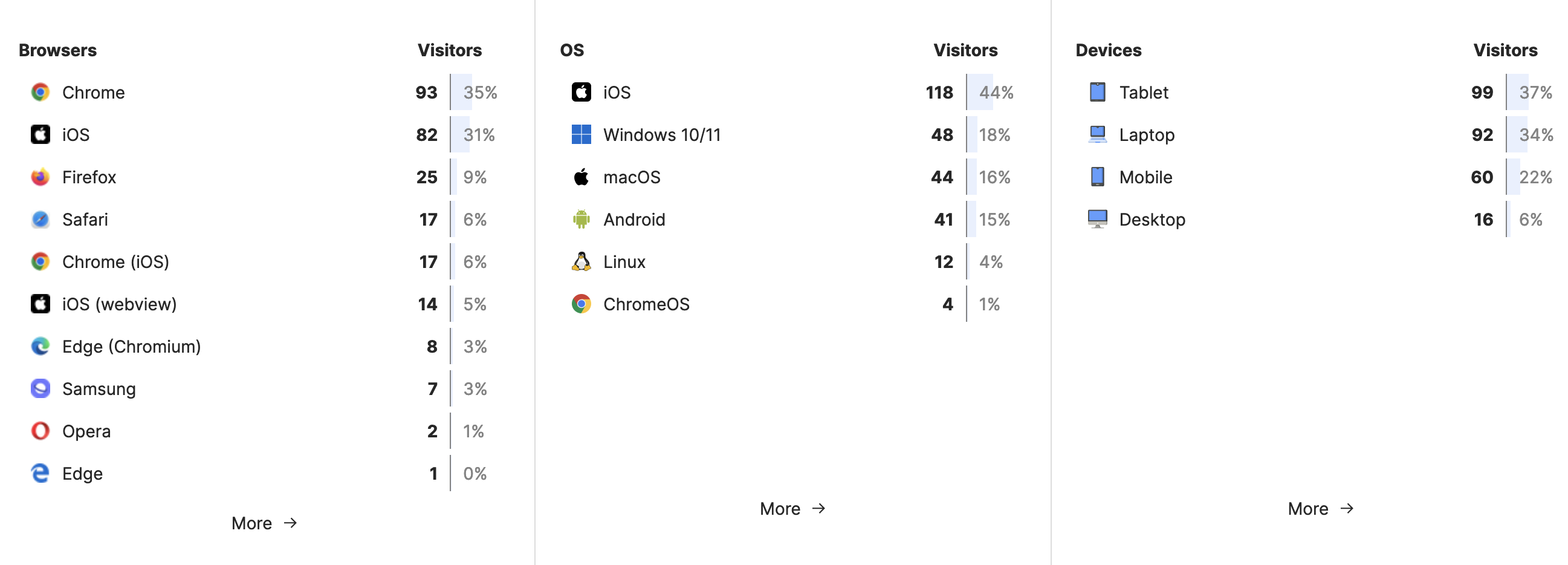
As you can see, it is quite fascinating to also see the different browsers and operating systems. I was surprised by two things:
- Apparently the Edge entry means pre-chormium edge. So I’m wondering which of my users has such an outdated system1.
- I’m also curious about who is using ChromeOS. I just remember having used ChromeOS some time ago at a high school in Australia, but have not seen the system since then.
Image resolutions
Since I’m displaying size optimised images on this website, I also wanted to know what the different devicePixelRatio measurements were. So I decided that after 10 seconds of staying on a page, that would qualify as someone actually ready the page and I would check their browser’s devicePixelRatio. This code is actually visible in the source code of ever page:
<script>
setTimeout(() => {
umami.track("reading",{devicePixelRatio: window.devicePixelRatio });
}, 10 * 1000);
</script>
Firstly, there are many resolutions and they are quite diverse. But making images for 1, 2 and 3, covers more than 90% of all devices exactly, meaning there is an image that matches exactly2. There are also much more, such as 2.625, or also 4.5. But since the browser’s will just download and display the image that matches the best, it’s not necessary to generate all of them (and Cloudflare has still not enabled Caching, so all these images would be regenerated for every build of this site)
Secondly, the more strange ones, such as 2.625 or 3.5 can still be quite prevalent, with both making up about 3% of the clicks. Which isn’t a whole lot, but it is something.
How many nines?
As always, if you are doing something for web, you need to decide how many nines you’d like to support. Some people want 99% of browser support and 99.999% uptime and so forth. For the image sizes, I decided to go with one single 9. After all, images still get displayed, so I don’t want to overdo it.
Maybe the system is not that outdated, after all I was recently asked to develop a web application with the requirements of supporting pre-chromium edge as well as Internet Explorer 11. 😱 ↩︎
This means the images are available in the normal resolution, 2x resolution and 3x resolution. This only happens if the images are large enough, as I currently don’t upscale images. ↩︎